How to use the batch processing module
How to use the batch processing module
At the moment the only available algorithm is:
- Density-based clustering of 2D objects
(DistributedClustering)
libraryDependencies ++= Seq(
"com.here.platform.location" %% "location-spark" % "<version>"
)
<dependencies>
<dependency>
<groupId>com.here.platform.location</groupId>
<artifactId>location-spark_${scala.compat.version}</artifactId>
</dependency>
</dependencies>dependencies {
compile group: 'com.here.platform.location', name: 'location-spark_2.13', version:'<version>'
}Clustering
The clustering algorithm implements a distributed version of
DBScan. It clusters geographically
spread, geolocated items. To exemplify what the algorithm does, see the
following image:
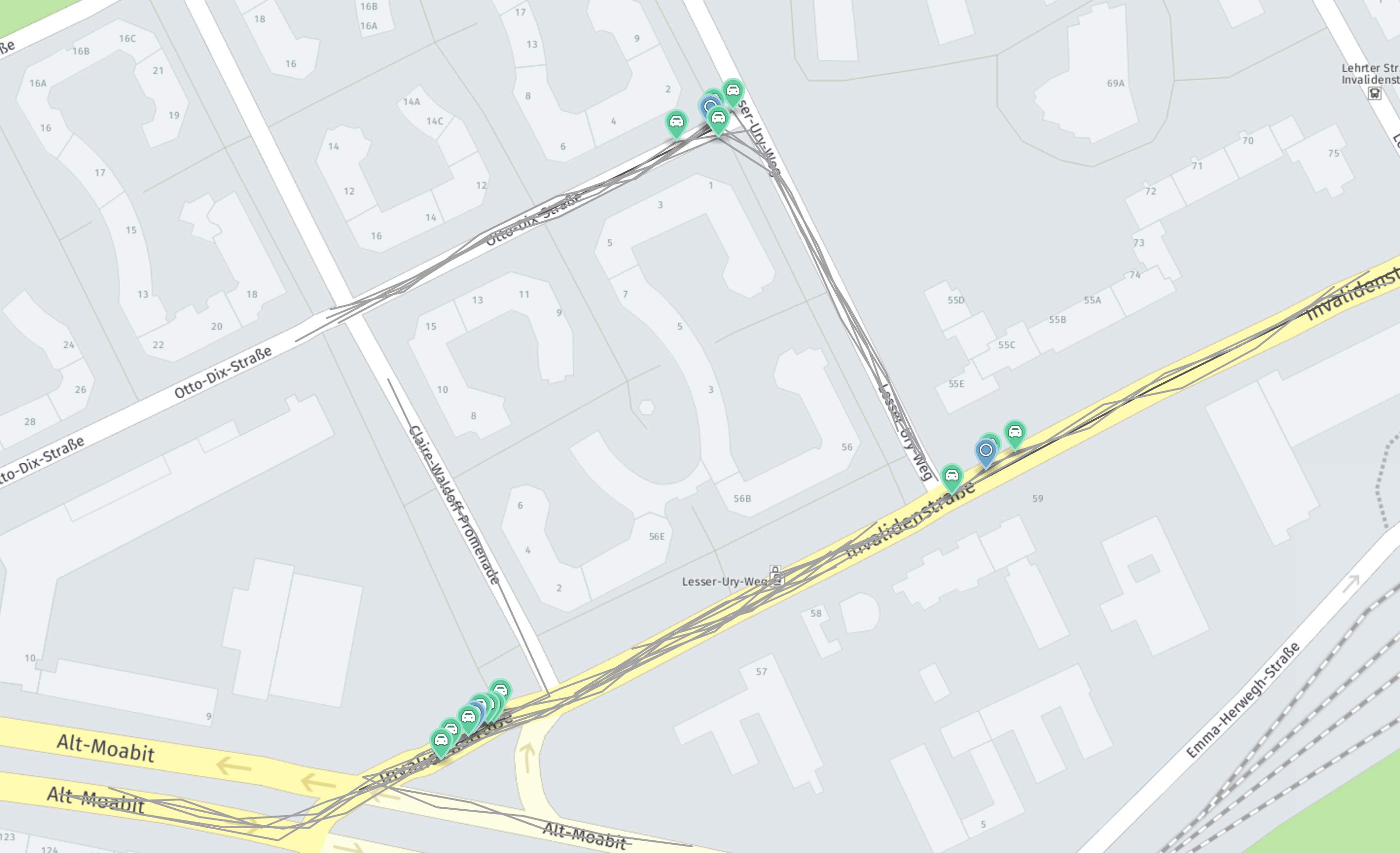
The input data contains different trips and events reported along them. These
events are marked in green. The image shows these clusters. For each of them, an
instance of
Cluster
is returned. The blue markers represent the cluster centers.
You can use
DistributedClustering
as follows:
import com.here.platform.location.spark.{Cluster, DistributedClustering}
import org.apache.spark.rdd.RDD
val events: RDD[Event] = mapPointsToEvents(sensorData)
val dc = new DistributedClustering[Event](neighborhoodRadiusInMeters = 20.0,
minNeighbors = 3,
partitionBufferZoneInMeters = 125.0)
val clusters: RDD[Cluster[EventWithPosition]] = dc(events)
val result = clusters.collect()
assert(result.nonEmpty)
// Print some statistics
val clusterCount = result.length
val clusteredEvents = result.map(_.events.length).sum.toDouble
println(s"Found $clusterCount clusters")
println(s"Found $clusteredEvents events in total.")
println(s"An average of ${clusteredEvents / clusterCount} event per cluster")You need an implicit instance of
GeoCoordinateOperations
to extract a GeoLocation that corresponds to your own Event type.